We use analytics and cookies to understand site traffic. Information about your use of our site is shared with Google for that purpose.You can read our privacy policies and terms of use etc by clicking here.
Troubleshooting
Seldon Deploy installs into standard kubernetes clusters and can be accessed by all modern browsers mentioned in the specifications.
Contact the Seldon team with the relevant issue and provide necessary details about your particular install of Seldon Deploy. The version details can be found at the about page of the tool that can be accessed from the user menu on the top-right corner.
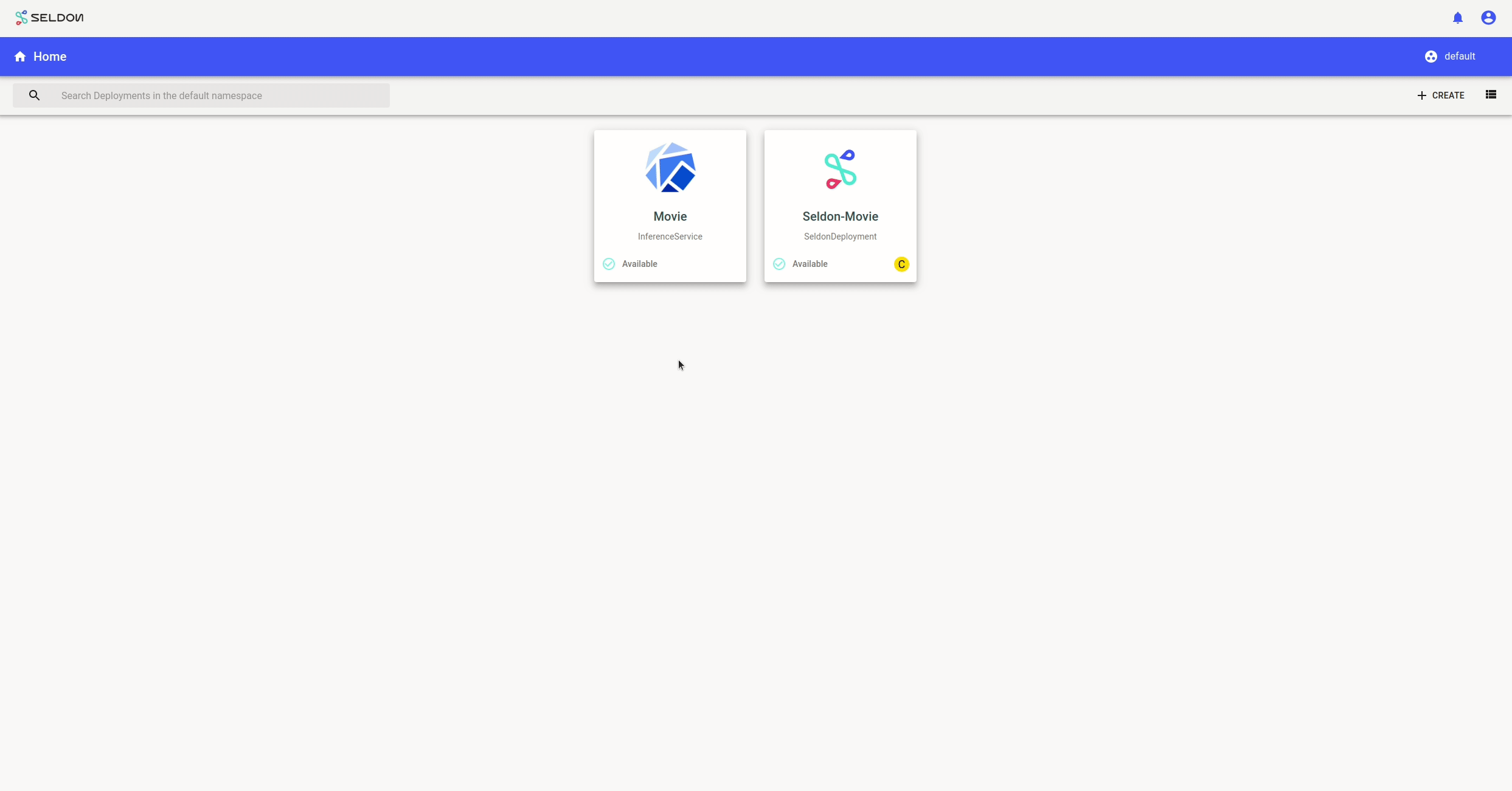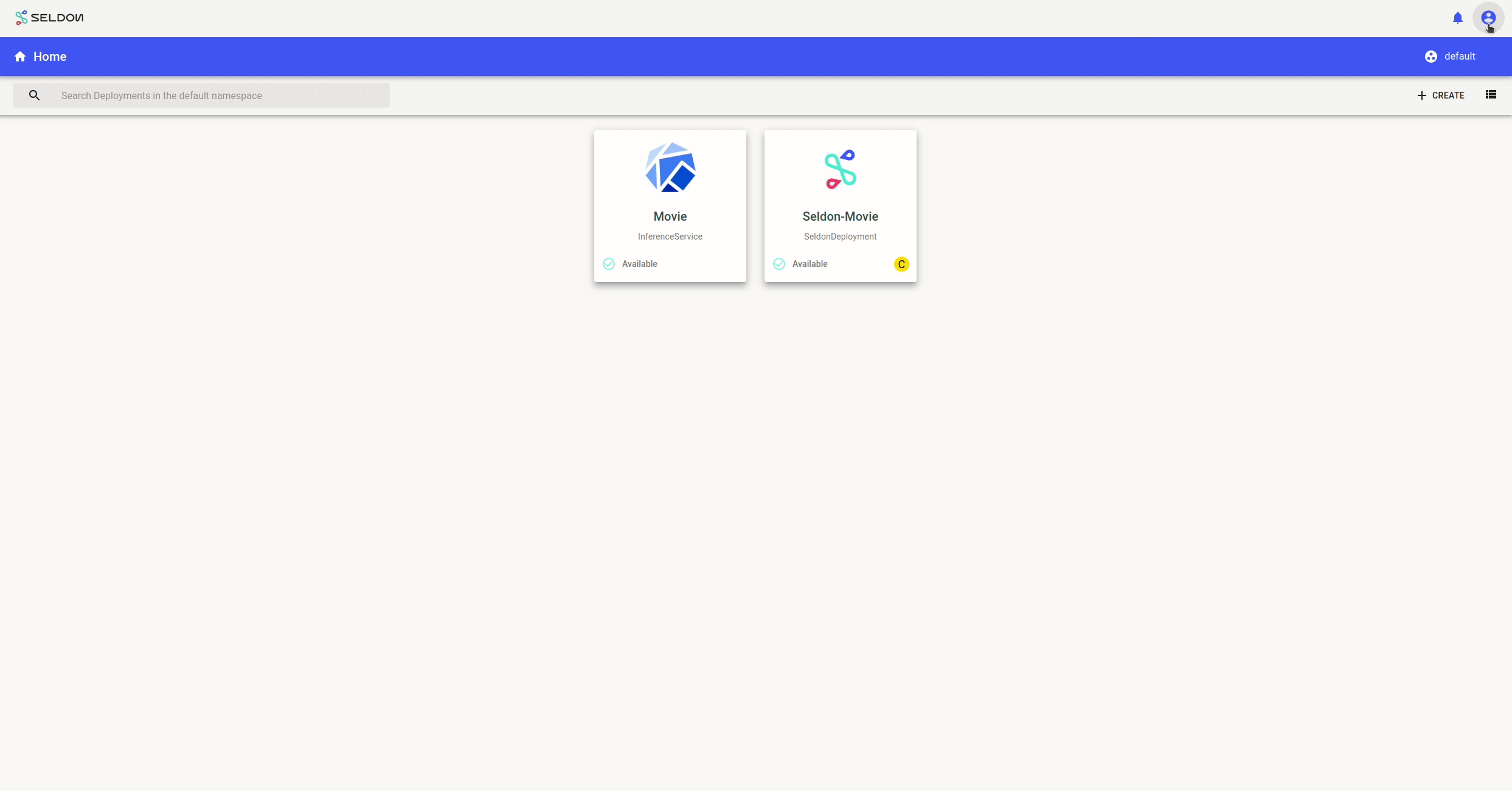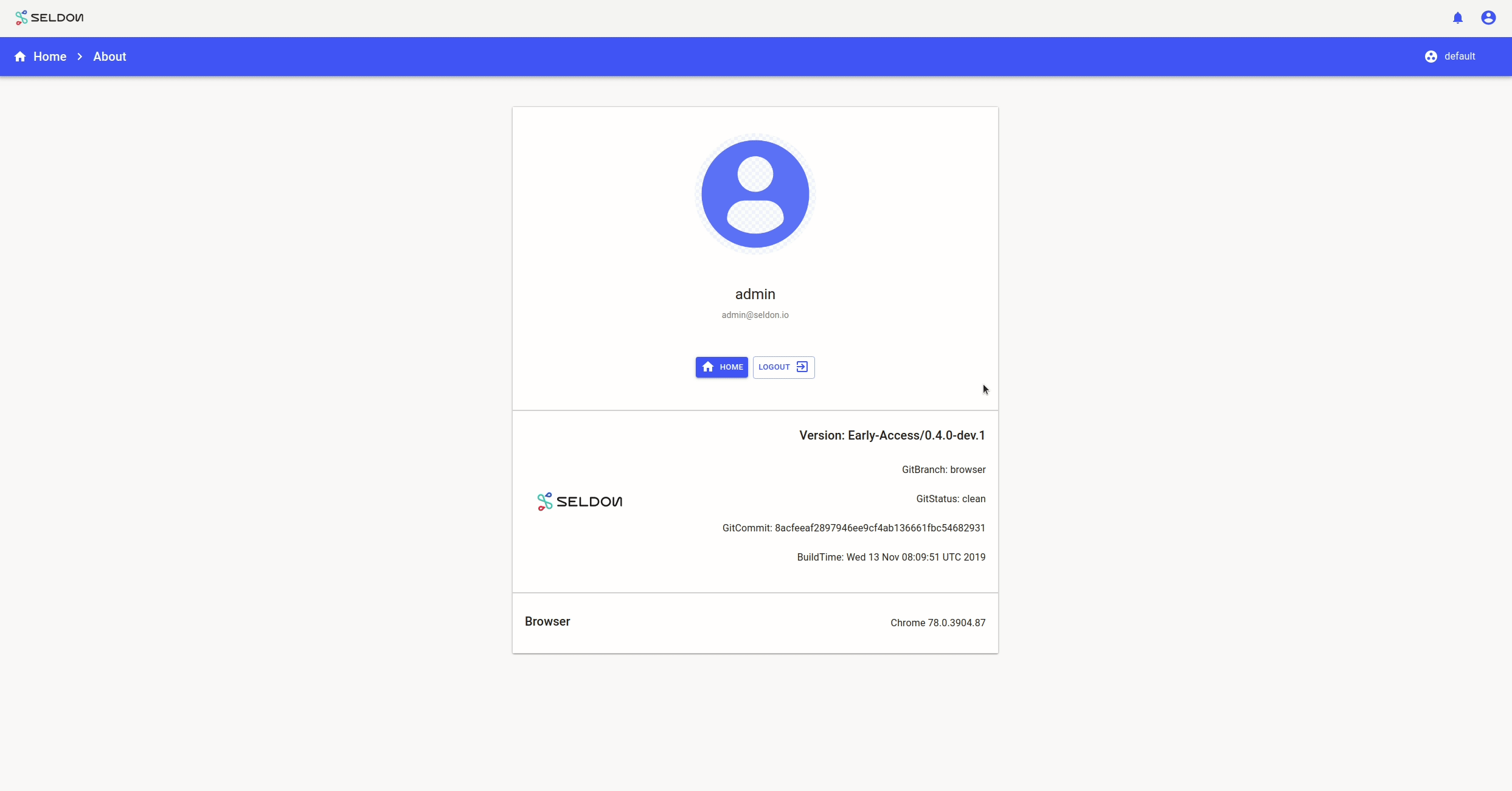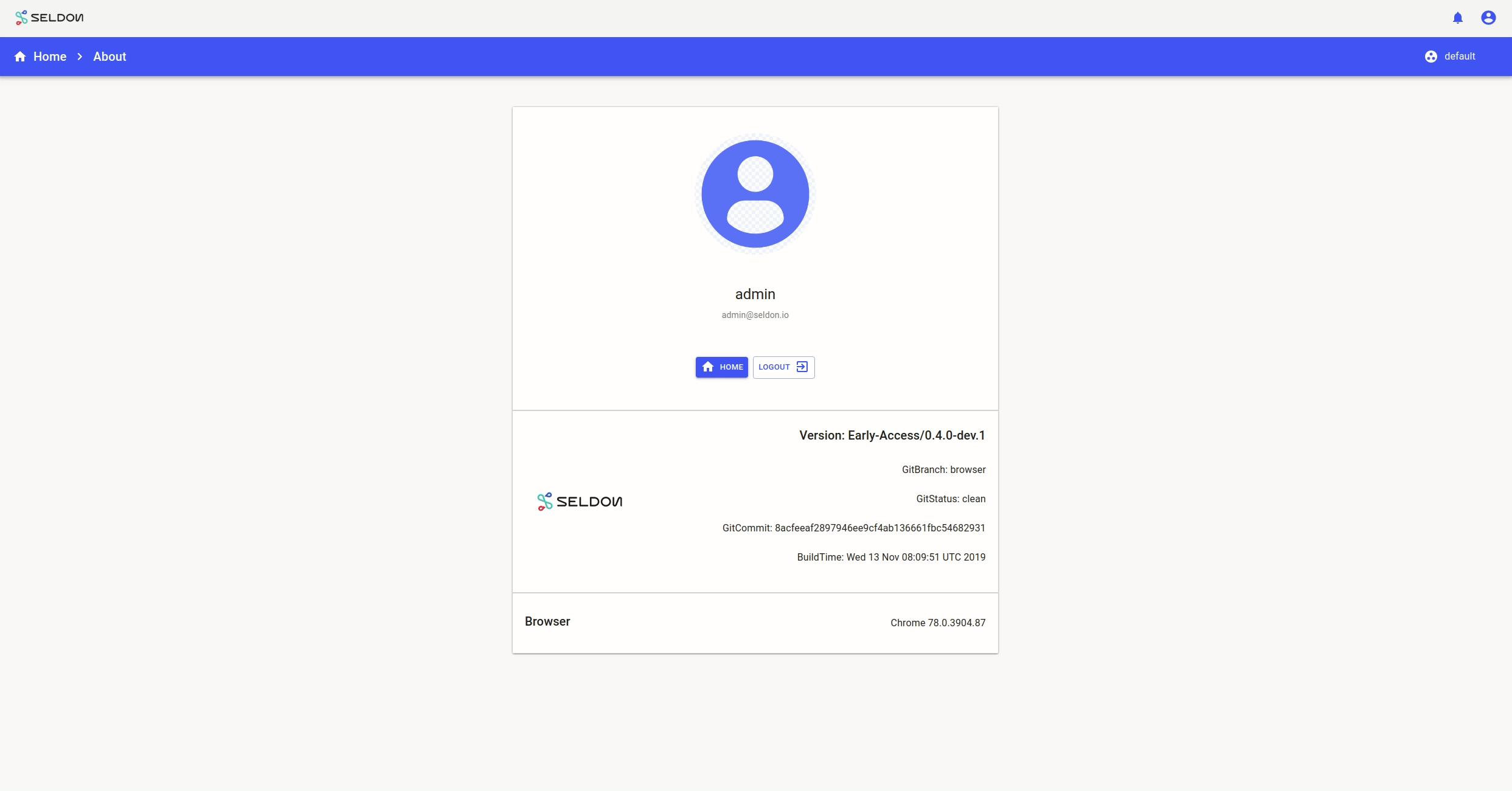
This about page displays the Seldon Deploy version details, license details and your browser version. For more details on your specific browser, please visit https://www.whatsmybrowser.org/ and share the URL that can provide us with more information about your browser usage like resolution and other support needed.
Browser Specifications
We recommend using the latest browser version available to your operating system. See your browser’s documentation to learn more about checking and updating your version. The project supports all modern browsers based on global usage (> 0.2%). The full list of browser versions supported include stable versions of Chrome, Firefox, Safari, Microsoft Edge and has a global coverage of 91.09%. The full set is listed here
and_chr 86
and_ff 82
and_uc 12.12
chrome 86
chrome 85
chrome 84
chrome 83
chrome 80
chrome 49
edge 86
edge 85
edge 18
firefox 82
firefox 81
ios_saf 14
ios_saf 13.4-13.7
ios_saf 13.3
ios_saf 12.2-12.4
ios_saf 10.3
ios_saf 9.3
opera 71
safari 14
safari 13.1
safari 13
samsung 12.0
Important browser settings To log into and edit your site, check if these browser settings are enabled or disabled in your browser:
- Cookies - Cookies must be enabled in your browser, per our Cookie Policy. Blocking cookies will interfere with editing your site. JavaScript - JavaScript must be enabled to edit your site. Avoid programs that block JavaScript, like anti-virus software.
- Browser add-ons or extensions - Browser add-ons might interfere with site editing. While disabling them isn’t always required, we may ask you to disable them when helping you troubleshoot.
- Browser window sizes Your computer’s screen size determines the maximum browser window resolution. For the best experience editing your site, use a browser window at least 1280 pixels wide and 768 pixels tall.
Errors from Seldon Deploy
If Seldon deploy crashes or returns an error the best first steps to get details are:
1) Turn on the network tab in the browser (via right-click and ‘Inspect’ in chrome), hit ‘Preserve Log’ and recreate the issue. Then find the failed call to see the full message. 2) Find the seldon deploy pod (usually in the seldon-system namespace) and inspect its logs.
This should help determine if the cause is seldon deploy or another component. If another component, see the other debugging sections from here. Either way the information obtained will be useful if an issue needs to be reported to Seldon.
Insufficient ephemeral storage in EKS clusters
When using eksctl, the volume size for each node will be of 20Gb by default.
However, with large images this may not be enough.
This is discussed at length on this
thread in the eksctl
repository.
When this happens, pods usually start to get evicted.
If you run kubectl describe on any of these pods, you should be able to see
errors about not enough ephemeral storage.
You should also be able to see some DiskPressure events on the output of
kubectl describe nodes.
To fix it, it should be enough to increase the available space.
With eksctl, you can do so by tweaking the nodeGroups config and adding a
volumeSize and volumeType keys.
For instance, to change the volume to 100Gb you could do the following in your
ClusterConfig spec:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
...
nodeGroups:
- volumeSize: 100
volumeType: gp2
...Elastic Queue Capacity
If request logging is used with a high throughput then it’s possible to hit a rejected execution of processing error in the logger.
This comes with a queue capacity message.
To address this the thread_pool.write.queue_size needs to be increased.
For example, with the elastic helm chart this could be:
esConfig:
elasticsearch.yml: |
thread_pool.write.queue_size: 2000
Request Logs Entries Missing
Sometimes requests fail to appear in the request logs. Often this is a problem with the request logger setup. If so see the request logging docs.
Sometimes we see this error in the request logger logs:
RequestError(400, 'illegal_argument_exception', 'mapper [request.instance] cannot be changed from type [long] to [float]')
What happens here is elastic has inferred the type of the fields in the request for the model’s index. This is inferred on the first request and if it changes or is inferred incorrectly this has to be addressed manually.
The best thing to do here is to delete the index.
First port-forward elastic. If the example elastic is used then this is kubectl port-forward -n seldon-logs svc/elasticsearch-opendistro-es-client-service 9200.
To delete the index we need to know its name. These follow a pattern. The pattern is:
inference-log-<seldon/kfserving>-<namespace>-<modelname>-<endpoint>
Usually endpoint is default unless there’s a canary.
You can also see indexes in kibana (in a trial install on /kibana/) or using the elastic API
Then delete the index with a curl. If the auth is admin/admin and there’s a cifar10 seldon model in a namespace also called seldon then it’s curl -k -v -XDELETE https://admin:admin@localhost:9200/inference-log-seldon-seldon-cifar10-default
Request Logs Entries Incorrect
Model names should not overlap as at the time of writing there is a bug with the request log page. Its searches can get confused between, say, ‘classifier’ and ‘classifier-one’. The logs in the backend are distinct but the searches can get muddled. This issue is being tracked - for now the workaround is to use distinct names.
Auth
See the auth section for debugging tips.
Knative
See the knative install section for how verify knative.
Argo and Batch
See the argo section for debugging batch and the minio section for minio.
Prometheus
See the metrics section for debugging prometheus.
Serving Engines
For Seldon Core and for KFServing debugging, it is best to see their respective docs.
In our demos we load models from google storage buckets. In the model logs we sometimes see this:
Compute Engine Metadata server unavailable onattempt
This is a known google storage issue but does not cause failures. Treat as a warning.
Last modified April 21, 2021